

¿Te gustaría aprender Ciencia de datos con Python?
Tenemos los cursos que necesitas. ¡Haz clic aquí!
Pandas es una biblioteca de código abierto de Python que proporciona análisis y manipulación de datos en la programación en Python.
Es una biblioteca muy prometedora de representación de datos, filtrado y programación estadística. La pieza más importante en pandas es el DataFrame donde almacena y juega con los datos.
En este tutorial, aprenderás qué es un DataFrame, cómo crearlo desde diferentes fuentes, cómo exportarlo a diferentes resultados y cómo manipular sus datos.
Instalar pandas
Puedes instalar pandas en Python usando pip. Ejecuta el siguiente comando en cmd:
pip install pandas
Además, puedes instalar pandas usando conda así:
conda install pandas
Leer un archivo de Excel
Puedes leer desde un archivo de Excel usando el método read_excel () de pandas. Para esto, necesitas importar un módulo más llamado xlrd.
Instala xlrd usando pip:
pip install xlrd
El siguiente ejemplo muestra cómo leer de una hoja de Excel:
- Creamos una hoja de Excel con los siguientes contenidos:
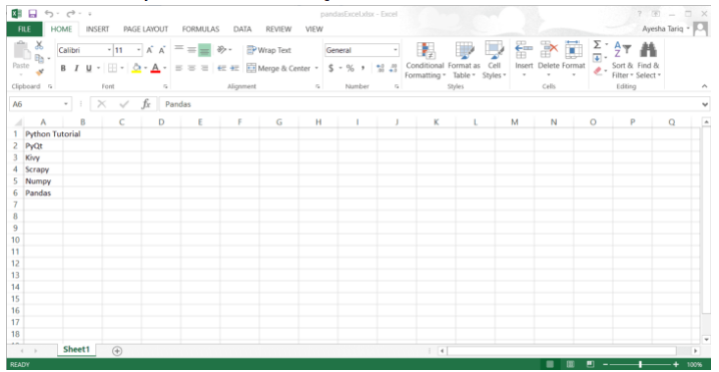
- Importa el módulo de pandas.
import pandas
- Pasaremos el nombre del archivo de Excel y el número de hoja del que necesitamos leer los datos al método read_excel ().
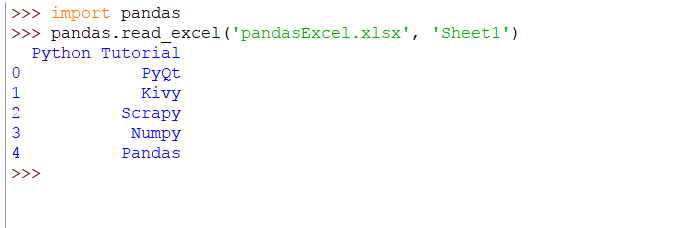
pandas.read_excel('pandasExcel.xlsx', 'Sheet1')
El fragmento anterior generará el siguiente resultado:
Si verificas el tipo de salida usando la palabra clave de type, te dará el siguiente resultado:
<class 'pandas.core.frame.DataFrame'>
¡Este resultado es llamado DataFrame! Esa es la unidad básica de pandas con la que vamos a tratar hasta el final del tutorial.
El DataFrame es una estructura de 2 dimensiones etiquetada donde podemos almacenar datos de diferentes tipos. DataFrame es similar a una tabla SQL o una hoja de cálculo de Excel.
Importar archivo CSV
Para leer un archivo CSV, puedes usar el método read_csv () de pandas.
Ad by Valueimpression
Importa el módulo de pandas:
import pandas
Ahora llama al método read_csv () de la siguiente manera:
pandas.read_csv('Book1.csv')
Book1.csv tiene el siguiente contenido:
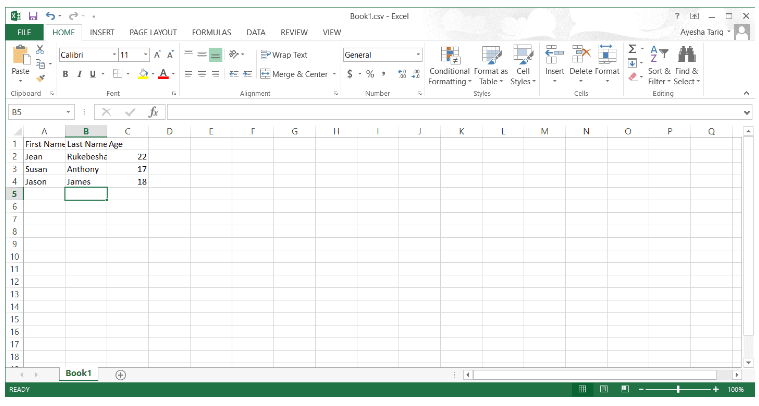
El código generará el siguiente DataFrame:

Leer un archivo de texto
También podemos usar el método read_csv de pandas para leer desde un archivo de texto; Considera el siguiente ejemplo:
import pandas
pandas.read_csv('myFile.txt')
El myFile.txt tiene el siguiente formato:
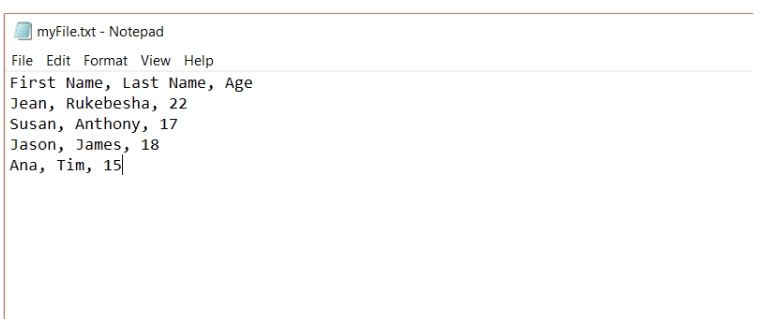
La salida del código anterior será:
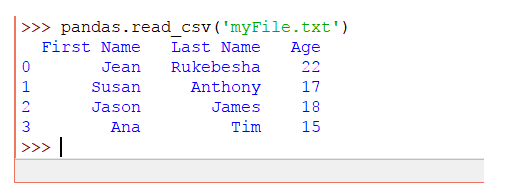
Este archivo de texto se trata como un archivo CSV porque tenemos elementos separados por comas. El archivo también puede usar otro delimitador, como un punto y coma, un tabulador, etc.
Supongamos que tenemos un delimitador de tabulador y el archivo se ve así:
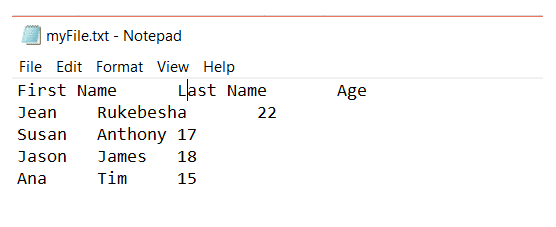
Cuando el delimitador es una un tabulador, tendremos el siguiente resultado:
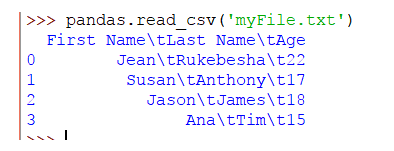
Como pandas no tiene idea del delimitador, traduce el tabulador a \ t.
Para definir el carácter de tabulación como un delimitador, pase el argumento delimiter de esta manera:
pandas.read_csv('myFile.txt', delimiter='\t')
Ahora la salida será:
Ad by Valueimpression
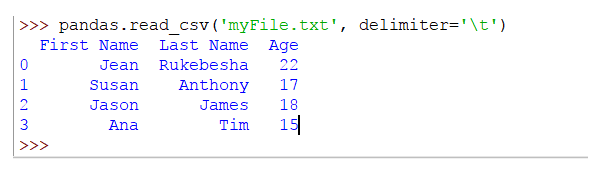
Parece correcto ahora.
Leer SQL
Puede usar el método read_sql () de pandas para leer desde una base de datos SQL. Esto se demuestra en el siguiente ejemplo:
import sqlite3
import pandas
con = sqlite3.connect('mydatabase.db')
pandas.read_sql('select * from Employee', con)
En este ejemplo, nos conectamos a una base de datos SQLite3 que tiene una tabla llamada “Empleado”. Usando el método read_sql () de pandas, pasamos una consulta y un objeto de conexión al método read_sql (). La consulta recupera todos los datos de la tabla.
Nuestra tabla de empleados se parece a la siguiente:
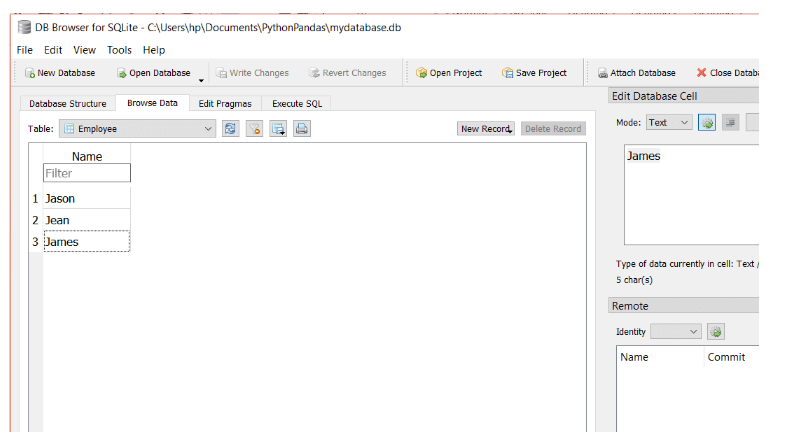
Cuando ejecutes el código anterior, la salida será como la siguiente:
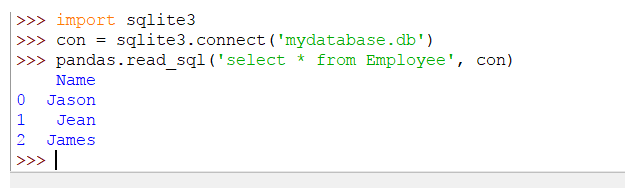
Seleccionar columnas
Supongamos que tenemos tres columnas en la tabla Empleado de esta manera:
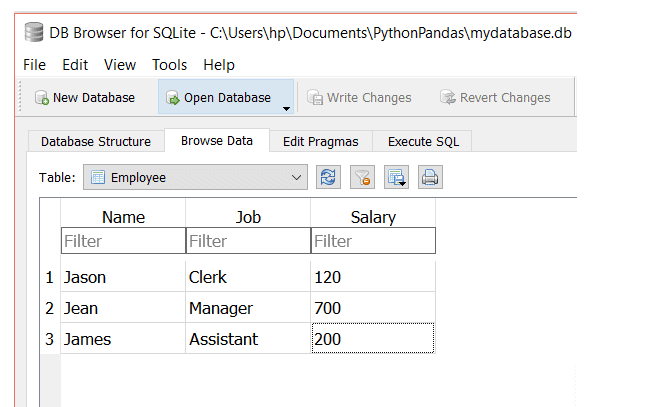
Para seleccionar columnas de la tabla, pasaremos la siguiente consulta:
select Name, Job from Employee
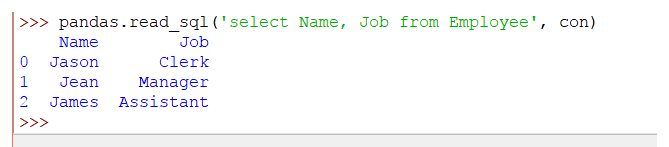
La sentencia del código de pandas será la siguiente:
pandas.read_sql('select Name, Job from Employee', con)
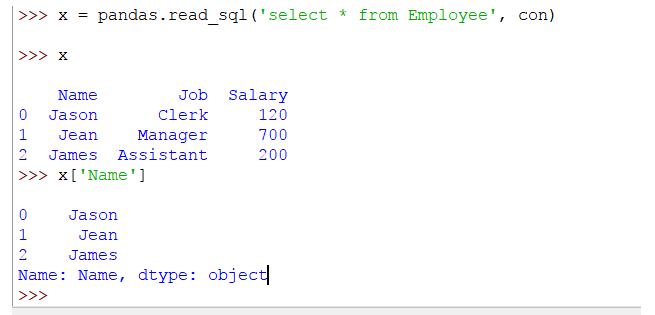
También podemos seleccionar una columna de una tabla accediendo al DataFrame a. Considera el siguiente ejemplo:
x = pandas.read_sql('select * from Employee', con)
x['Name']
El resultado será el siguiente:
Seleccionar filas por valor
Primero, crearemos un DataFrame desde el cual seleccionaremos filas.
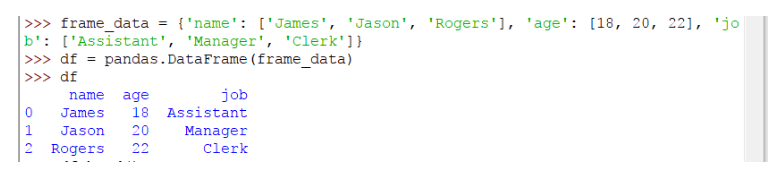
Para crear un DataFrame, considera el siguiente código:
import pandas
frame_data = {'name': ['James', 'Jason', 'Rogers'], 'age': [18, 20, 22], 'job': ['Assistant', 'Manager', 'Clerk']}
df = pandas.DataFrame(frame_data)
En este código, creamos un DataFrame con tres columnas y tres filas usando el método DataFrame () de pandas. El resultado será el siguiente:
Para seleccionar una fila de acuerdo a su valor, ejecute la siguiente sentencia
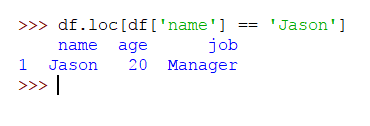
df.loc[df['name'] == 'Jason']
df.loc [] o DataFrame.loc [] es una arreglo booleano que se puede usar para acceder a filas o columnas mediante valores o etiquetas. En el código anterior, se buscará la fila donde el nombre es igual a Jason.
La salida será:
Seleccionar fila por índice
Para seleccionar una fila por su índice, podemos usar el operador de segmentación (:) o el arreglo df.loc [].
Considera el siguiente código:
>>> frame_data = {'name': ['James', 'Jason', 'Rogers'], 'age': [18, 20, 22], 'job': ['Assistant', 'Manager', 'Clerk']}
>>> df = pandas.DataFrame(frame_data)
Creamos un DataFrame. Ahora vamos a acceder a una fila usando df.loc []:
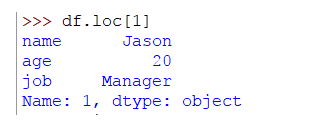
>>> df.loc[1]
Como puedes ver, recuperamos una fila. Podemos
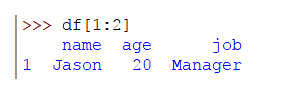
hacer lo mismo usando el operador de segmentación de la siguiente manera:
>>> df[1:2]
Cambiar tipo de columna
El tipo de datos de una columna se puede cambiar usando el atributo astype () de DataFrame. Para verificar el tipo de datos de las columnas, usamos el atributo dtypes de DataFrame.
>>> df.dtypes
La salida será:

Ad by Valueimpression
Ahora para convertir el tipo de datos de uno a otro:
>>> df.name = df.name.astype(str)
Buscamos la columna ‘name’ de nuestro DataFrame y cambiamos su tipo de datos de objeto a cadena de caracteres.
Aplicar una función a columnas / filas
Para aplicar una función en una columna o fila, puedes usar el método apply () de DataFrame.
Considere el siguiente ejemplo:
>>> frame_data = {'A': [1, 2, 3], 'B': [18, 20, 22], 'C': [54, 12, 13]}
>>> df = pandas.DataFrame(frame_data)
Creamos un DataFrame y agregamos valores de tipo entero en las filas. Para aplicar una función, por ejemplo, la raíz cuadrada en los valores, importaremos el módulo numpy para usar la función sqrt de esta manera:
>>> import numpy as np >>> df.apply(np.sqrt)
La salida será la siguiente:
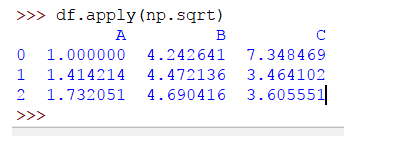
Para aplicar una función de suma, el código será:
>>> df.apply(np.sum)
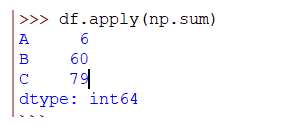
Para aplicar la función a una columna especifica, puedes especificar la columna de la siguiente forma:
>>>df['A'].apply(np.sqrt)
Ordenar valores / ordenar por columna
Para ordenar los valores en un DataFrame, utiliza el método sort_values () del DataFrame.
Crea un DataFrame con valores enteros:
>>> frame_data = {'A': [23, 12, 30], 'B': [18, 20, 22], 'C': [54, 112, 13]}
>>> df = pandas.DataFrame(frame_data)
Ahora para ordenar los valores:
>>> df.sort_values(by=['A'])
La salida será:

El método sort_values () tiene un atributo “by” que es necesario. En el código anterior, los valores se ordenan por la columna A. Para ordenar por varias columnas, el código es el siguiente:
>>> df.sort_values(by=['A', 'B'])
Si desea ordenar en orden descendente, establece el atributo ascending de set_values en False de la siguiente manera:
>>> df.sort_values(by=['A'], ascending=False)
La salida será:

Quitar / Eliminar duplicados
Para eliminar filas duplicadas de un DataFrame, usa el método drop_duplicates () del DataFrame.
Considera el siguiente ejemplo:
>>> frame_data = {'name': ['James', 'Jason', 'Rogers', 'Jason'], 'age': [18, 20, 22, 20], 'job': ['Assistant', 'Manager', 'Clerk', 'Manager']}
>>> df = pandas.DataFrame(frame_data)
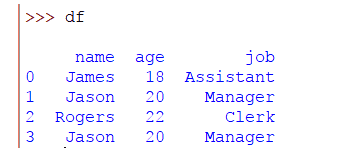
Aquí creamos un DataFrame con una fila duplicada. Para verificar si hay filas duplicadas en el DataFrame, usa el método duplicated () del DataFrame.
>>> df.duplicated()
El resultado será:
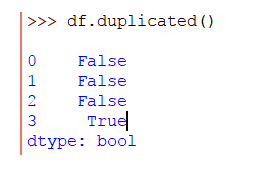
Se puede ver que la última fila es un duplicado. Para eliminar esta fila, ejecuta la siguiente línea de código:
>>> df.drop_duplicates()
Ahora el resultado será:
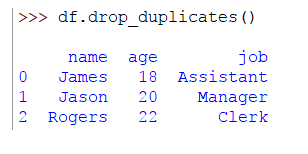
Eliminar duplicados por columna
A veces, tenemos datos en los que los valores de las columnas son los mismos y deseamos eliminarlos. Podemos eliminar una fila por columna al pasar el nombre de la columna que debemos eliminar.
Por ejemplo, tenemos el siguiente DataFrame:
>>> frame_data = {'name': ['James', 'Jason', 'Rogers', 'Jason'], 'age': [18, 20, 22, 21], 'job': ['Assistant', 'Manager', 'Clerk', 'Employee']}
>>> df = pandas.DataFrame(frame_data)
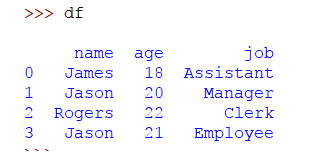
Aquí puedes ver que Jason esta dos veces. Si desea eliminar duplicados por columna, simplemente pasa el nombre de la columna de la siguiente manera:
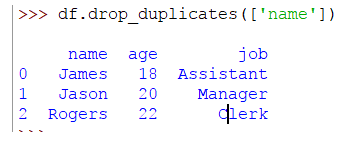
>>> df.drop_duplicates(['name'])
El resultado será como el siguiente:
Borrar una columna
Para eliminar una columna o fila completa, podemos usar el método drop () del DataFrame especificando el nombre de la columna o fila.
Considera el siguiente ejemplo:
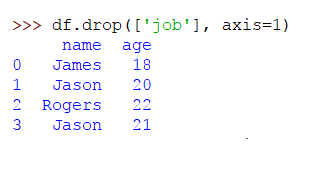
>>> df.drop(['job'], axis=1)
En esta línea de código, estamos eliminando la columna llamada “job”. El argumento del eje es necesario aquí. Si el valor del eje es 1 significa que queremos eliminar columnas, si el valor del eje es 0 significa que la fila se eliminará. En valores de eje, 0 es para índice y 1 para columnas.
El resultado será:
Eliminar filas
Podemos usar el método drop () para eliminar una fila al pasar el índice de la fila.
Supongamos que tenemos el siguiente DataFrame:
>>> frame_data = {'name': ['James', 'Jason', 'Rogers'], 'age': [18, 20, 22], 'job': ['Assistant', 'Manager', 'Clerk']}
>>> df = pandas.DataFrame(frame_data)
Para eliminar una fila con el índice 0 donde el nombre es James, la edad es 18 y el trabajo es asistente, utiliza el siguiente código:
>>> df.drop([0])
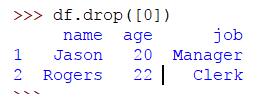
Vamos a crear un DataFrame donde los índices son los nombres:
>>> frame_data = {'name': ['James', 'Jason', 'Rogers'], 'age': [18, 20, 22], 'job': ['Assistant', 'Manager', 'Clerk']}
>>> df = pandas.DataFrame(frame_data, index = ['James', 'Jason', 'Rogers'])
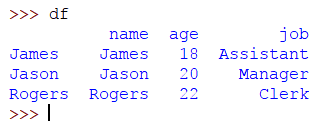
Ahora podemos eliminar una fila con un cierto valor. Por ejemplo, si queremos eliminar una fila donde el nombre es Rogers, entonces el código será:
>>> df.drop(['Rogers'])
La salida será:
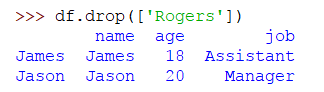
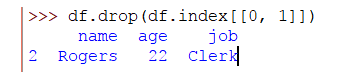
También puedes eliminar un rango de filas de la siguiente forma:
>>> df.drop(df.index[[0, 1]])
Esto eliminará las filas del índice 0 a 1 y solo quedará una fila ya que nuestro DataFrame se compone de 3 filas:
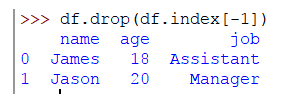
Si deseas eliminar la última fila del DataFrame y no sabe cuál es el número total de filas, puede utilizar la indexación negativa como se muestra a continuación:
>>> df.drop(df.index[-1])
-1 borra la última fila. Similarmente -2 borrará las últimas 2 filas y así sucesivamente.
Sumar una columna
Puede usar el método sum () del DataFrame para sumar los elementos de la columna.
Supongamos que tenemos el siguiente DataFrame:
>>> frame_data = {'A': [23, 12, 12], 'B': [18, 18, 22], 'C': [13, 112, 13]}
>>> df = pandas.DataFrame(frame_data)
Ahora para sumar los elementos de la columna A, usa la siguiente línea de código:
>>> df['A'].sum()

También puedes usar el método apply () del DataFrame y pasar el método de suma de numpy para sumar los valores.
Contar valores únicos
Para contar valores únicos en una columna, puedes usar el método nunique () del DataFrame.
Supongamos que tenemos un DataFrames como a continuación:
>>> frame_data = {'A': [23, 12, 12], 'B': [18, 18, 22], 'C': [13, 112, 13]}
>>> df = pandas.DataFrame(frame_data)
Para contar los valores únicos en la columna A:
>>> df['A'].nunique()

Como puedes ver, la columna A tiene solo 2 valores únicos 23 y 12 y el otro 12 es un duplicado, por eso tenemos 2 en la salida.
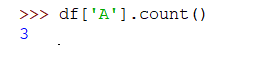
Si desea contar todos los valores en una columna, puedes usar el método count () de la siguiente manera:
>>> df['A'].count()
Filas de subconjuntos
Para seleccionar un subconjunto de un DataFrame, puedes usar los corchetes.
Por ejemplo, tenemos un DataFrame que contiene algunos enteros. Podemos seleccionar o buscar el subconjunto de una fila de esta forma:
df.[start:count]
El punto de inicio se incluirá en el subconjunto, pero el punto de parada no se incluye. Por ejemplo, para seleccionar 3 filas a partir de la primera fila, escribirás:
>>> df[0:3]

Ese código significa comenzar desde la primera fila que es 0 y selecciona 3 filas.
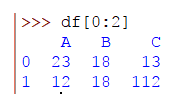
Del mismo modo, para seleccionar las primeras 2 filas, escribirás:
>>> df[0:2]
Para seleccionar o buscar un subconjunto con la última fila, usa la indexación negativa:
>>> df[-1:]

Escribir a un Excel
Para escribir un DataFrame en una hoja de Excel, podemos usar el método to_excel ().
Para escribir en una hoja de Excel, tiene que abrir la hoja y para abrir una hoja de Excel, tendremos que importar el módulo openpyxl.
Instala openpyxl usando pip:
pip install openpyxl
Considera el siguiente ejemplo:
>>> import openpyxl
>>> frame_data = {'name': ['James', 'Jason', 'Rogers'], 'age': [18, 20, 22], 'job': ['Assistant', 'Manager', 'Clerk']}
>>> df = pandas.DataFrame(frame_data)
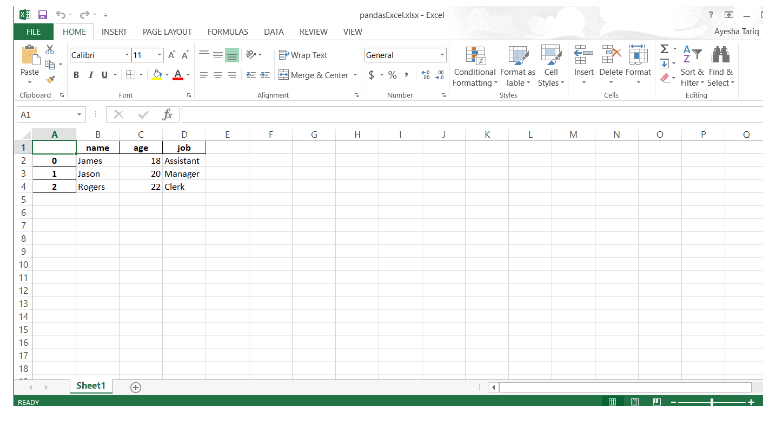
>>> df.to_excel("pandasExcel.xlsx", "Sheet1")
El archivo de Excel se verá como el siguiente:
Escribir a un archivo CSV
De manera similar, para escribir un DataFrame en CSV, puede usar el método to_csv () como se muestra en la siguiente línea de código.
>>> df.to_csv("pandasCSV.csv")
El archivo de salida será como el siguiente:
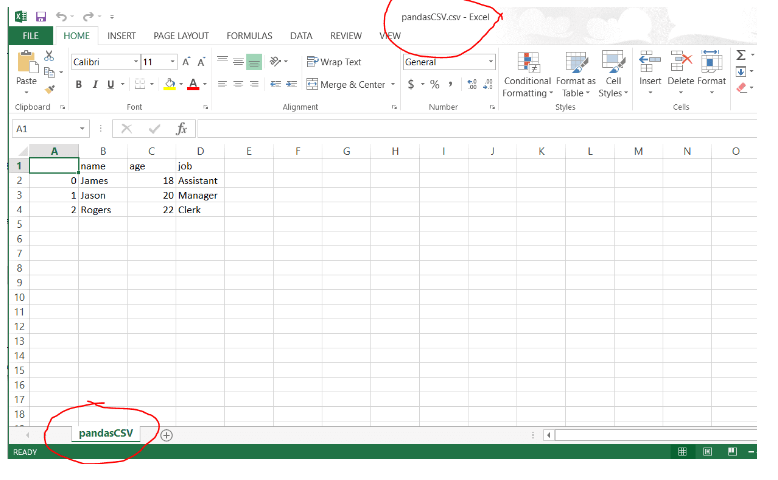
Escribir a SQL
Para escribir datos en SQL, podemos usar el método to_sql ().
Considera el siguiente ejemplo:
import sqlite3
import pandas
con = sqlite3.connect('mydatabase.db')
frame_data = {'name': ['James', 'Jason', 'Rogers'], 'age': [18, 20, 22], 'job': ['Assistant', 'Manager', 'Clerk']}
df = pandas.DataFrame(frame_data)
df.to_sql('users', con)
En este código, creamos una conexión con una base de datos sqlite3. Luego creamos un DataFrame con tres filas y tres columnas.
Finalmente, utilizamos el método to_sql de nuestro DataFrame (df) y pasamos el nombre de la tabla donde se almacenarán los datos junto con el objeto de conexión.
La base de datos SQL se verá de la siguiente forma:
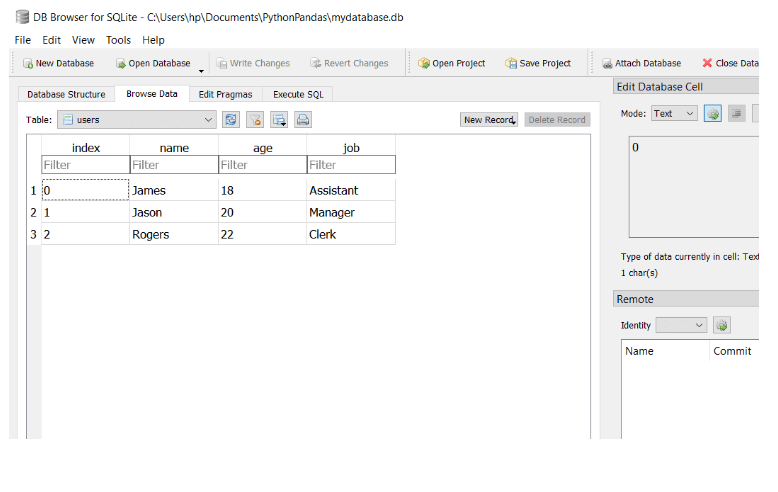
Escribir a JSON
Puede usar el método to_json () del DataFrame para escribir en un archivo JSON.
Esto se demuestra en el siguiente ejemplo:
>>> df.to_json("myJson.json")
En esta línea de código, el nombre del archivo JSON se pasa como un argumento. El DataFrame se almacenará en el archivo JSON. El archivo tendrá el siguiente contenido:
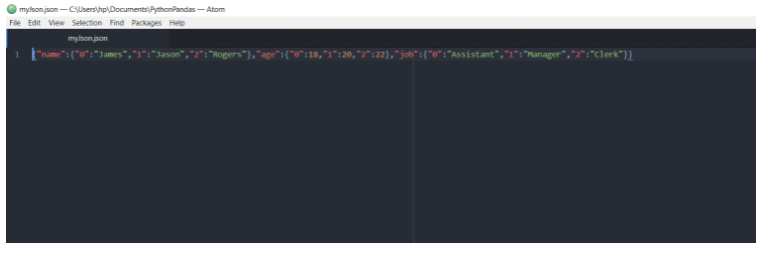
Escribir en un archivo HTML
Puede usar el método to_html () del DataFrame para crear un archivo HTML con el contenido del DataFrame.
Considera el siguiente ejemplo:
>>> df.to_html("myhtml.html")
El archivo de resultados tendrá el siguiente contenido:
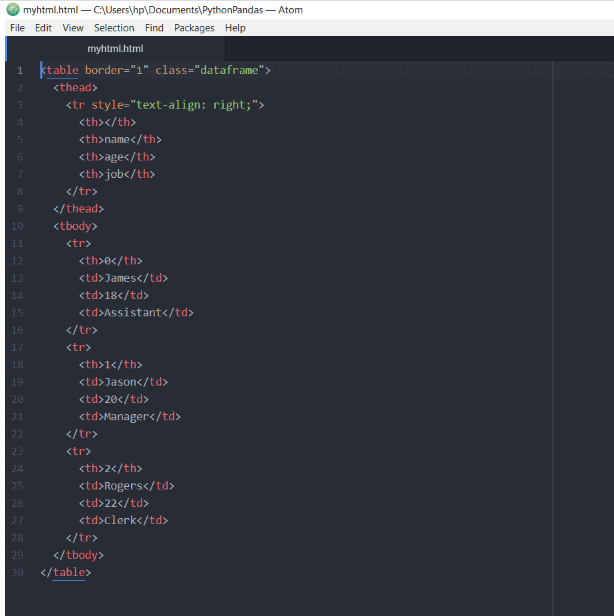
Cuando abras el archivo HTML en el navegador, se verá así:
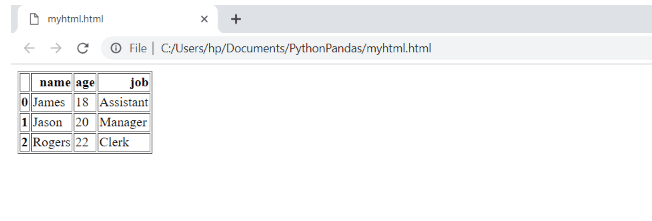
Como vez trabajar con pandas es muy fácil. ¡Es como trabajar con hojas de Excel! Pandas DataFrame es una biblioteca muy flexible que puedes usar.
Te esperamos en los siguientes artículos en donde hablaremos más acerca de estos temas, los cuales hoy en día son de vital importancia en el mundo de la tecnología.
¿Te gustaría aprender Ciencia de datos con Python?
Tenemos los cursos que necesitas. ¡Haz clic aquí!




