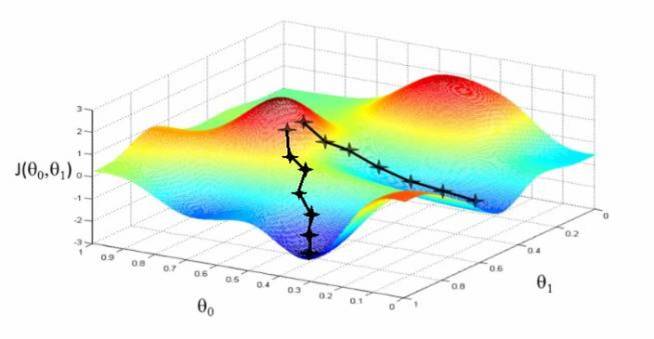
esto lo hace en base a algún algoritmo de aprendizaje. En la actualidad hay muchos, que suelen ser variaciones del algoritmo clásico de retropropagación del error (‘error backpropagation’, propuesto en 1986 por David Rumelhart, Geoffrey Hinton y Ronald Williams). La idea básica es que, si empezamos con unos pesos aleatorios para las conexiones entre las neuronas, las neuronas de salida nos darán un resultado que no se ajusta para nada a las etiquetas de las que disponemos para cada ejemplo. Esta falta de ajuste se puede codificar como un error, que es el que eventualmente queremos minimizar. En otras palabras, buscamos ajustar los valores de los pesos de forma que el error que obtengamos en las neuronas de salida sea el mínimo posible. En términos matemáticos estaríamos hablando de optimizar la función de error.
Y precisamente lo que se usa en el método de la retropropagación es un algoritmo de optimización, más concretamente el llamado descenso de gradientes. Así, tras un cálculo de derivadas sencillo, podemos entender cómo se propaga ese error por cada una de las capas de la red neuronal, y tras un número de iteraciones (que pueden ser pocas o muchas, en función de los datos en cuestión) el algoritmo tiende a encontrar los valores de los pesos que dan un error mínimo.
Aquí es importante hacer notar que el sistema en ningún caso está guardando los dígitos con que se ha entrenado, y buscando a cuál se parece más el nuevo que estamos probando, sino que ‘aprende’ a través de los ejemplos qué diferencia a un 1 de un 2, de un 3, de un 4, etcétera. Esto implica que cuantos más ejemplos le pasemos, aprenderá mejor, pero el tamaño de la red no aumenta porque el diseño físico de la misma no ha cambiado, solamente lo han hecho sus pesos. Se trata de un esquema muy parecido a como un niño aprende a distinguir dígitos, en base a ver muchos, y de ahí que a menudo a este tipo de aplicaciones se las denomine cognitivas.
En lingo técnico, la misión fundamental de los modelos de aprendizaje supervisado es la de clasificación y regresión, es decir, obtener el parámetro o etiqueta de salida en base a unos parámetros de entrada. Durante el entrenamiento de la red se le suministra el parámetro de salida para que aprenda, pero luego ésta tiene que hacerlo sola, dando una predicción. En nuestro ejemplo concreto los parámetros de entrada son los dígitos escritos a mano, y el de salida es el número que representan, y por lo tanto hablamos de una tarea de clasificación. Cuando en lugar de dígitos discretos lo que buscamos es un parámetro continuo, se le denomina regresión.
Por otro lado, el aprendizaje no-supervisado funciona sin tener acceso a las etiquetas de cada ejemplo suministrado. La idea no es tanto lograr una tarea predictiva, si no descriptiva, de forma que seamos capaces de extraer conocimiento intrínseco de los datos en base a unos algoritmos que calculan cómo se parecen entre sí los ejemplos, o qué tipo de asociaciones existen en los diferentes elementos que componen los ejemplos. El caso típico es la separación en varios grupos de los puntos sobre un gráfico de dispersión, conocido como agrupamiento o ‘clustering’.
Para este tipo de tareas no se necesitan etiquetas, ya que el propio algoritmo clasifica cada ejemplo en función del resto de ejemplos. Por ello, en estos casos es común que se necesite guardar en memoria todos los ejemplos y evaluarlos una vez entre el ejemplo de prueba, lo que se conoce como ‘lazy-learning’.
Si bien también ha habido líneas de investigación para aplicar estos métodos no-supervisados a problemas de clasificación, lo cierto es que estos no han logrado el mismo nivel de éxito que los supervisados. A día de hoy, el aprendizaje no-supervisado se suele usar como un paso previo al desarrollo de una red neuronal, que casi siempre es ya de tipo deep, para facilitar el aprendizaje de la misma.
Deep Learning 2012: tecnología, modelos y datos
Una pregunta muy natural que el lector puede tener llegado a este punto es: si esta tecnología funciona, y sus fundamentos matemáticos existen desde los años 80, ¿por qué se ha convertido en una moda sólo ahora? La razón está anclada a consideraciones tecnológicas y empresariales. A nivel comercial el desarrollo de aplicaciones ha sido lento, ya que no existían demasiados casos de éxito técnicos que pudieran ser trasladados a ambientes prácticos. El más famoso fue el del hoy director del laboratorio de IA de Facebook, Yann LeCun, conocido como la red LeNet-5, una red neuronal convolucional (un tipo de red que simula cómo el cerebro distingue patrones en las imágenes) con 5 capas desarrollada entre 1989 y 1998. La misión era, precisamente, el reconocimiento de dígitos escritos a mano, y se implementó eficazmente tanto en la oficina postal de EEUU como en bancos, que llegaron a leer entre el 10-20% de sus cheques mediante este sistema.

Desde esa época hasta el 2012 siguió habiendo avances en la investigación de las arquitecturas neuronales y los métodos de aprendizaje, pero no salieron de un contexto académico. De hecho, el campo de las redes neuronales (como disciplina informática) vivió uno de sus peores inviernos precisamente entre 2000 y 2008, cuando su dificultad para encontrarles aplicaciones, y la explosión del universo digital, hizo que sus activistas quedaran relegados a despachos en universidades. Pero fue precisamente ese universo digital, y en concreto las redes sociales, las que irónicamente jugaron un papel determinante en su revitalización.
Como hemos explicado antes, el principal paradigma del aprendizaje automático es que, frente a otros paradigmas de Inteligencia Artificial, los algoritmos de ‘Machine Learning’ aprenden en base a ejemplos. Es decir, necesitan de datos para poder desarrollar su ‘inteligencia’ y ser de utilidad. Y justo los datos de tipo cognitivo (imágenes, texto, audios…) comenzaron a crecer exponencialmente con la llegada de la digitalización. Por un lado la gente estaba generando ingentes cantidades de datos (fundamentalmente en redes sociales y en plataformas web), y además la tecnología necesaria para almacenarlos y procesarlos en un tiempo razonable estaba avanzando a grandes pasos.
Así, la cuestión entonces era aplicar todos esos modelos matemáticos, que se llevaban décadas preparando y creando en las universidades, precisamente sobre esos nuevos datos. En este sentido, se encontraron con que la primera dificultad era la mala escalabilidad en el tiempo que tenían estos algoritmos, al nutrirles de una cantidad de información tan grande. Efectivamente teníamos muchos más datos con que alimentar a la redes neuronales para que éstas aprendieran, pero tardaban demasiado en entrenarse, o simplemente eran incapaces de hacerlo eficazmente.
Sin embargo, afortunadamente, contábamos también con otro agente tecnológico externo que acudió en ayuda: la computación paralela, y más concretamente las GPU (acrónimo del inglés ‘graphical processing units’) o tarjetas gráficas. Éstas, que originariamente habían sido concebidas para hacer cálculos masivos de operaciones matriciales (las que se usan para el renderizado de píxeles en imágenes) resultaron perfectamente idóneas para ayudar a los investigadores a paralelizar sus tareas de entrenamiento de las redes neuronales.

Tanto, que en 2012 un grupo de investigación de la Universidad de Toronto liderado por Geoff Hinton (el mismo de la retropropagación) usó dos de estas tarjetas para entrenar una red convolucional con 650.000 neuronas, en base a 1.200.000 imágenes de alta definición. Esta red, conocida como AlexNet, entró en la Competición ImageNet de 2012, y ganó el premio en la prueba de reconocimiento Error de Test Top-5, alcanzando un error del 15.3% en la clasificación de 150.000 fotografías (de mil tipos distintos) de Flickr. Sus competidores, que eran equipos expertos en el campo de la Visión Computacional, y cuyos avances de año en año eran de escasos puntos porcentuales, quedaron por encima de 26%. Es decir, que AlexNet resultó rompedora en el campo. ¡Tanto que en la ILSVRC-2013 todos los participantes presentaron una red neuronal del mismo estilo!
Desde entonces, (casi) todas las aplicaciones de visión computacional tienen su base en las redes convolucionales, y últimamente las más mediáticas vienen en forma de conducción automática, promulgadas por empresas como Tesla, Uber o Google, empresa a la que fueron a trabajar en 2013 los tres autores de AlexNet. Y el ‘Deep Learning’ no sólo ha impactado el tratamiento de imágenes, sino también el reconocimiento de voz, donde asistentes personales como Siri (propiedad de Apple), Alexa (de Amazon) u OK Google se basan en redes neuronales recurrentes.
Te esperamos en los siguientes artículos en donde hablaremos mas acerca de estos temas, los cuales hoy en día son de vital importancia en el mundo de la tecnología.